It was as something of an afterthought that we added to the Tag Assignment program (WORDTAG) and the Tag Selection program (CHAINPROBS) a third, intermediate program (IDIOMTAG) to deal with various grammatically anomalous word-sequences which, without intending any technical usage of the term, we may call 'idioms'. 4
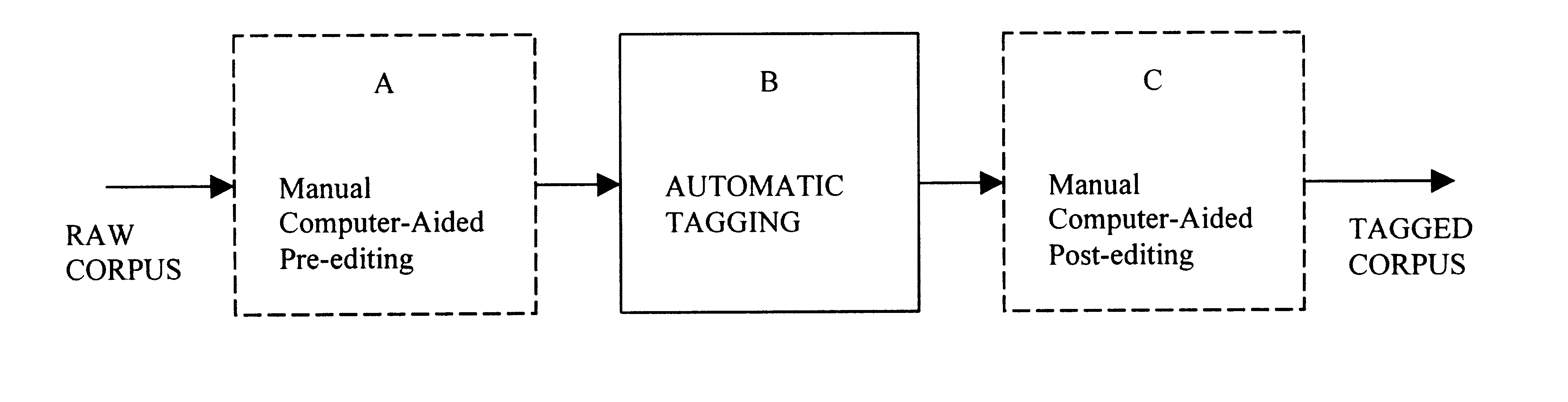
4.1 Pre-editingWhen the Verticalization of the corpus took place, another set of programs produced 'Editlists' of particular text features which had to be checked by a human editor to see whether they had to be altered in order to be suitable input to the Automatic Tagging. The most important lists were those of 'CAPITALS' (non- sentence- initial words beginning with a capital letter) and 'UNCAPITALS' (sentence-initial words whose capital letter would have been changed to lower case by the Verticalization program). For example, if a sentence began with a proper name such as John, the program changed this to john, and a manual editor had to change it back again. The reason for these changes in capitalisation was that the Automatic Tagging programs made use of word-initial capitals in deciding what kind of tags to assign to a word (most words beginning with a capital end up being tagged as proper nouns; see 7.7 and Appendix 3).
Although the majority of pre-editing changes were made automatically by the Verticalization program, Pre-editing proved to be a time-consuming process, especially since all pre-editing decisions had to be carefully standardized and entered in a 'Pre-editing Manual'. In a subsequent tagging project we are now trying to eliminate manual pre-editing, by enabling the automatic tagging programs to accept a word with an initial capital as a possible variant of a lower case word. 5
4.2 Tag AssignmentThe Tag Assignment Program reads each word in turn, and carries out a series of testing procedures, to decide how the word should be tagged. The procedures are crucially ordered, so that if one procedure fails to tag a word, the word drops, through through to the next procedure. In the rare cases where none of the tag-assignment procedures is successful, the word is given a set of default tags. The program's structure can be summarized at its simplest by listing the major procedures as follows (where W = the word currently being tagged):
|
(1) |
Is W in the WORDLIST? |
|
(2) |
Is W a number, a single letter, or a letter preceded or followed by a number of digits? |
|
(3) |
Does W contain a hyphen? |
|
(4) |
Does W have a word-initial capital (WIC)? |
|
(5) |
Does W end with one of the endings in the SUFFIXLIST? |
|
(6) |
Does W end in -s? |
|
(7) |
If none of the above apply, assign default tags for words not ending in -s. |
APPLYHYPHEN and APPLYWIC are 'macroprocedures' which themselves consist of a set of tests comparable to those of the main program. For further details, see the Flowcharts in Appendices 1-3.
The output of the Tag Assignment Program is a version of the Vertical Corpus, in which one or more grammatical tags (with accompanying rarity markers @ or % if appropriate)7 are centered alongside each word. As an additional useful feature, this program provides a diagnostic (in the form of an integer between 0 and 100) indicating the tagging decision which led to the tag-assignment of each word. This enables the efficacy of each procedure in the program to he monitored, so that any improvement effected by changes in the program can be measured and analysed. In this respect, the program is self-evaluating. It can also be readily updated through revisions to the Tag-set, Wordlist, or Suffixlist.
4.3 Tag Selection
![]()
![]()
If one part of the project can be said to have made a particular contribution to automatic language processing, it is the Tag Selection Program (CHAINPROBS). the structure of which is described in greater detail in Marshall (1983). This program operates on a principle quite different from that of the Tag Selection part of the program used on the Brown Corpus. The Brown program used a set of CONTEXT FRAME RULES, which eliminated tags on the current word if they were incompatible with tags on the words within a span of two to the left or two to the right of the current word (W). Thus assuming a sequence of words -2, -1. W, +1, +2, an attempt was made to disambiguate W on the evidence of tags already unambiguously assigned to words -2, -1, +1, or +2. The rules worked only if one or more of these words were unambiguously tagged, and consequently often failed on sequences of ambiguous words. Moreover, as many as 80% of the applications of the Context Frame Rules made use of only one word to the left or to the right of W. These observations, made by running the Brown Program over part of the LOB Corpus, led us to develop, as a prototype of the LOB Tag-Selection Program, a program which computes transitional probabilities between one tag and the next for all combinations of possible tags, and chooses the most likely path through a set of ambiguous tags on this basis.
Given a sequence of ambiguous tags, the prototype Tag-Selection Program computed all possible combinations of tag-sequences (i.e. all possible paths), building up a search tree. It treated each possible Tag Sequence or path as a first-order Markov chain, assigning to each path a probability relative to other paths, and reducing by a constant scaling factor the likelihood of sequences containing tags marked with a rarity marker @ or %. Our assumption was that the frequency of tag sequences in the Tagged Brown Corpus would be a good guide to the probability of such sequences in the LOB Corpus; these frequencies were therefore extracted from the Brown Corpus data, and adjusted to take account of changes we had made to the Brown Tag-set. We expected that the choice of tags on the basis of first-order probabilities would provide a rough-and-ready tag-selection procedure which would then have to be refined to take account of higher-order probabilities. It is generally assumed, following Chomsky (1957:18-25) that a first-order Markov process is an inadequate model of human language. We therefore found it encouraging that the success rate of this simple first-order probabilistic algorithm, when tried out on a sample of over 15,000 words of the LOB Corpus, was as high as 94%. An example of the output of this program (from Marshall 1983) is given in Fig 3:
Fig 3
|
this |
DT |
|
task |
NN |
|
involved |
[VBD]/90 VBN/10 JJ@/0 |
|
a |
AT |
|
very |
[QL]/99 JJB@/1 |
|
great |
[JJ]/98 RB/2 |
|
deal |
[NN]/99 VB/1 |
|
of |
IN |
|
detailed |
[JJ]/98 VBN/2 VBD/0 |
|
work |
[NN]/100 VB/0 |
|
for |
[IN]/97 CS/3 |
|
the |
ATI |
|
committee |
NN |
In this output, the tags supplied by the Tag Assignment Program are accompanied by a probability expressed as a percentage. For example, the entry for the word involved ([VBD]/90 VBN/10 JJ@/0) indicates that the tag VBD 'past tense verb' has an estimated probability of 90%; that the tag VBN 'past participle' has an estimated probability of 10%; and that the tag M 'adjective' has an estimated probability of 0%. The symbol @ after M means that the Tag Assignment program has already marked the 'adjective' tag as rare for this word. The square brackets enclosing the 'past tense' tag indicate that this tag has been selected as correct by the Tag Selection Program. (The square brackets are used to indicate the preferred tag for every word that is marked as ambiguous; where the word has only one assigned tag, this marking is omitted as unnecessary.)
An improved Tag Selection Program was developed as a result of an analysis of the errors made by the prototype program. We realised that an attempt to supplement the first-order transition matrix by a second-order matrix would lead to a vast increase in the amount of data to be handled as part of the program. with only a marginal increase in the program's success. A more practical approach would be to concentrate on those limited areas where failure to take account of longer sequences resulted in errors, and to introduce a scaling factor to adjust such sequences in the direction of the desired result. For instance, the occurrence of an adverb between two verb forms (as in has recently visited) often led to the mistaken selection of VBD rather than VBN for the second verb,
and this mistake could be corrected by downgrading the likelihood of a triple consisting of the verb be or have followed by an adverb followed by a past tense verb. Similarly, many errors resulted from sequences such as live and work, where we would expect the same word-class to occur on either side of the coordinator - something which an algorithm using frequency of tag-pairs alone could not predict. This again could be handled by boosting or reducing the predicted likelihood of certain tag triples. A further useful addition to the program was an alternative method of calculating relative likelihood, making use of the probability of a word's belonging to a particular grammatical class, rather than the probability of the occurrence of a whole sequence of tags. This serves as a cross-check on the 'sequence-probability' method, and appears to be more accurate for some classes of cases. These improvements, together with the introduction of an Idiom Tagging Program (see 4.4 below), resulted in an overall success rate of between 96.0% and 97.0%. (This calculation excludes punctuation tags, which are automatically 'correct'.)
4.4 Idiom Tagging
![]()
![]()
The third tagging program, which intervenes between the Tag Assignment and Tag Selection programs, is an Idiom Tagging Program (IDIOMTAG) developed as a means of dealing with idiosyncratic word sequences which would otherwise cause difficulty for the automatic tagging. One set of anomalous cases consists of sequences which are best treated, grammatically, as a single word: for example, in order that is tagged as a single conjunction, as to as a single preposition, and each other as a single pronoun. Another group consists of sequences in which a given word-type is associated with a neighbouring grammatical category; for example, preceding the preposition by, a word like invoked is usually a past participle rather than a past tense verb. The Idiom Tagging Program is flexible in the sorts of sequence it can recognize, and in the sorts of operation it can perform: it can look either at the tags associated with a word, or at the word itself; it can look at any combination of words and tags, with or without intervening words. It can delete tags, add tags, or change the probability of tags. It uses an Idiom Dictionary to which new entries may be added as they arise in the corpus. In theory, the program can handle any number of idiomatic sequences, and thereby anticipate likely mis-taggings by the Tag Selection Program; in practice, in the LOB Corpus tagging project, the program was used in a rather limited way, to deal with a few areas of difficulty. Although this program might seem to be an ad hoe device, it is worth bearing in mind that any fully automatic language analysis system has to come to terms with problems of lexical idiosyncrasy.
4.5 Post-editing
![]()
![]()
The Vertical Corpus, after automatic tagging, contained, alongside each word, one or more grammatical tags, placed in order of their likelihood of occurring in this context. The tag selected by the program as the correct one was already indicated (see the example in 4.3). To simplify the task of the post-editor, a threshold was set below which the likelihood of error was low enough to be disregarded at the initial stage of post-editing. Sample analyses had shown that 60% of the text-words were unambiguously tagged; that of the 40% which were ambiguously tagged, 64% had a likelihood, as calculated by the Tag Selection Program of more than 90%; and that these had only a 0.5% risk of being erroneous. This means that over the whole sample 86% of words could be unambiguously tagged with less than 1% error. In these relatively safe cases, the output listing simply assumed the one tag to be correct, and gave alternative taggings only for the 14% of words for which the risk of error was relatively high.
The computer programs achieved a level of success in identifying the correct tag of between 96% and 97%. In spite of the very high success rate, there remained a very large number of errors to be corrected. Post-editing proved to be a laborious and time-consuming process. Initially, post-editors read through the running text to identify tagging errors. This was followed by a good deal of consistency checking based on concordance listings for selected words. All errors which were discovered were corrected and the two versions of the corpus (cf Section 2) and the KWIC concordance (cf ![]()
![]()