![]() COLT-based research
COLT-based research
The COLT material was collected in London by a research team at the University of Bergen in 1993. It consists of roughly half-a-million words of spontaneous conversations between 13- to 17-year old boys and girls from socially different school districts. During the period 1994-95, the conversations were transcribed orthographically (including indication of pauses and overlapping speech) by transcribers engaged by the Longman Group, and tagged for word-classes by a team at Lancaster university. In this form, COLT has become part of the British National Corpus (BNC).
At this point, the entire corpus has been checked and edited by the team in Bergen. The frequent occurrence of <unclear> labels and the numerous instances of a question mark for speaker identity in the original transcripts indicate that the transcribers were faced with considerable problems. During our checking process, a great many instances of <unclear> have disappeared, most of the speakers have been identified, and mistakes in the original transcription have been straightened out. As a result, we have not only ended up with a transcription that is more faithful to the tape-recordings but also with a larger corpus; the number of words has increased by at least 15 per cent. This, in turn, has had the effect that the original word class tagging has become partly inadequate and that the edited corpus will have to be retagged.
The retagging, which will be done by means of the Xanthippe software with assistance from Lancaster university, will be completed at the beginning of the autumn. A first, orthographically transcribed, word class-tagged version of COLT, with a search program, will then be produced on CD-ROM with help from the Norwegian Computer Centre for the Humanities at the University of Bergen, and will be launched in the autumn of 1998. To obtain a copy of COLT I, please contact Knut Hofland or Anna-Brita Stenström.
The next stage involves the production of a second, more sophisticated version of COLT on CD-ROM. This will include sound files and a prosodically annotated version in addition to the orthographically transcribed text. The prosodically annotated version, however, does not comprise the whole corpus. A limited number of texts have been selected, taking the recruits themselves as a staring point. Three criteria - age, sex and socioeconomic group - were used so that the percentage of each in the prosodically annotated version should more or less match the whole corpus. The prosodic analysis has been carried out by research assistants at the University of Bergen, and involves chunking the speech into tone units by marking the nucleus and the tone unit boundary.
From the outset of the COLT-project, it has been a stated aim to launch a final version of the corpus including sound files comprising the actual recordings of the conversations that have been transcribed. The advantage of this is obvious: it enables the researcher to make judgements as to the phonemic and phonological properties of the recorded speech, and to analyze prosodic aspects such as pitch, loudness, tempo and rhythm in a much more subtle way than our simplified prosodic marking of the texts will allow.
We are now in the progress of producing the second CD-ROM. Initially, all the audio-recorded material will be digitized using the sound-editing program Cool Edit. Then, the digitized material will be divided into sound files of standard length, each sound file corresponding to an unspecified number of words in the text. We are not certain which time-span will be optimal, but it seems clear that each sound file will not exceed 20 seconds. To ensure cohesion, the sound files will overlap by approximately two seconds.
Any other editing, such as deleting names and improving the sound quality, will also be performed at this stage. The sound quality varies a lot from one recording to the next. The fact that quite a few of the conversations took place on the bus, near a road with heavy traffic, in the school playground or in very noisy classrooms (!) underlines the need for sound editing of the recordings. However, the removal of disturbing noise takes place at a certain risk and must be performed with caution to avoid the sound of the actual conversations being impaired.
Finally, the concordance of sound and text requires a re-indexation of the texts, including the insertion of a tag which indicates where one sound file ends and the next begins. The links from text to sound files will allow the researcher to access the audio version of the corpus by a mere mouse-click on the extract s/he wants to listen to.

COLT material has provided the basis for both PhD and MA theses at the university of Bergen. Five MA theses have already been completed (Andersen, unpublished; Berland, unpublished; Bynes, unpublished; Hasund,unpublished; Straume, unpublished; Tandberg, unpublished); and four are under way, on the following topics: 'Backchannelling', 'Vague language' and 'Storytelling'. One PhD dissertation, on 'Age-specific discourse strategies', is also under way. Most of these studies are sociolinguistic in nature. In some, relevance theory is adopted for interpreting utterances. Finally, two PhD students, who are researching learner language, use COLT conversations for comparison.
Small samples of COLT are also used for research outside Bergen, e.g. at Stockholm university and Åbo Academy, and guest students from abroad have spent time at the COLT project to be able to study the entire corpus as well as listen to the recordings.
Pragmatic markers in teenage and adult conversation
Gisle Andersen, Home page, University of Bergen, 1997
This paper involves a comparison of COLT (The Bergen Corpus of Teenage Language) and the spoken component of the British National Corpus. The purpose of the comparison is to observe whether there are distributional differences between teenage and adult conversation in the use of pragmatic markers, ie words such as cos, like, innit, well, oh, which contribute very little to the semantic content of utterances but which serve important pragmatic functions. The main objective is to test the hypothesis put forward by Eriksson (1991), Kotsinas (1994) and others, that teenagers apply words of this kind with greater frequency than adults, which is said to reflect the highly emotive and expressive nature of teenage speech and the fact that teenagers frequently employ so-called 'high-involvement style' (Tannen 1984). Although several studies suggest that a high-marker frequency is a typical phenomenon of teenage speech, there seems to be a lack of studies which include comparative quantitative data to support this hypothesis. The comparison of the two corpora also has a qualitative aspect. Pragmatic markers are typically multifunctional, and the analysis of variation in marker use also involves assessing whether the markers serve the same pragmatic functions in teenage and adult speech.
More trends in teenage talk
A corpus-based investigation of the discourse items cos and
innit
Gisle Andersen and Anna-Brita Stenström, University of Bergen, 1996
Teenage language can be expected to differ form the standard language not only in terms of vocabulary and pronunciation but also grammar and pragmatics. To some extent, such differences have already been demonstrated in earlier studies of British and American teenage language (Labov 1972; Cheshire 1982;
Romaine 1984; Eckert 1988; Stenström 1994; Andersen 1995; Kerswill 1995). These studies indicate that teenage language is characterized by features that are rare or do not occur at all in the standard language and that, up to a point, it is governed by other factors than adult language.This paper presents an investigation of the discourse items cos and innit in the Bergen Corpus of Teenage Language (COLT). For comparison, we have used the
London-Lund Corpus of Spoken English , which has the same size but consists of conversations between adult, educated British speakers in London, collected mainly in the 1960s (cf Svartvik & Quirk 1980). The choice of cos and innit as objects of study is motivated by two main factors. One is that cos has a different distribution and partly different functions in COLT and LLC, while the form innit does not occur at all in LLC; another is that cos and innit, although different in nature, appear to develop in the same direction in the London teenage vernacular, from sentence components to 'extra-sentential' pragmatic particles.


They like wanna see like how we talk and all that
The use of like as a discourse marker in London
teenage speech
Gisle Andersen, University of Bergen, 1996
This paper focuses on the use and pragmatic function of the highly frequent word like in the speech of London teenagers. Numerous examples from the Bergen Corpus of London Teenage Language (COLT) show that like has a wide range of uses, many of which do not fit the labels which categorize this word in Standard English (eg verb or preposition / conjunction), and like can therefore be considered a multifunctional discourse marker. This characterization is
however slightly problematic since like is commonly more syntactically integrated than discourse markers in general. The paper also assesses how the discourse marker like correlates with the parameter social class.
Girls' conflict talk: a sociolinguistic investigation of variation in the verbal disputes of
adolescent females
Anna-Brita Stenström and Ingrid Kristine Hasund, University of Bergen, 1996
This paper is about variation in the disputes of London teenage girls. The main aim of our study has been to test the frequently held assumption that girls tend to avoid direct and
competitive arguments, preferring instead to deal with conflict in a more indirect and co-operative manner. There is evidence to believe that such an assumption is too simplistic, and that there is far more variation in the dispute skills performed by females than has often been suggested.
The primary material for this study is a subcorpus of COLT (The Bergen Corpus of London Teenage Language), consisting of some of the conversations some 13 to 17 year old female recruits had with their friends. We isoloated all the disputes these recruits had with their friends. We isolated all the disputes these recruits had with their female friends, playful as well as serious. Even though no disputes between
girls and boys were analyzed, some conversations where male participants were present were included. This was done to see whether girls tend to argue differently among themselves in the
presence of males than in all-female groups. The focus is on direct conflict only, and not on indirect conflict talk such as gossip.
The methodology used is Conversation Analysis combined with ethnographic information from field notes. The analysis of the sequential patterning of the disputes was followed by an analysis of the structural organisation of the arguments as reflective of the participation framework created in each
particular conversation. In other words, conflict talk is analysed both on the micro-level of internal structure and on the macro-level of social organisation.
The results show that girls do participate in different types of conflict exchanges, developing different types of conflict skills. This undermines the commonly accepted notion that there exists a single, homogeneous feminine speech style. The paper demonstrates that the relation between gender
and conflict talk should be regarded not as static but rather as variable and highly context-specific.


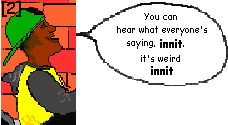
I goes you hang it up in your shower, innit ? He goes yeah.
The use and development of invariant tags in London teenage speech
Gisle Andersen, University of Bergen, 1997
This paper investigates what seems to be a fairly recent innovation in the London teenage vernacular - the invariant use of the constructions innit and is it. Originally canonical questions regarding person-, tense- and number agreement, these constructions frequently occur as invariant tags in present-day adolescent speech. Such a development has previously been attested in the Englishes of Papua New Guinea, Singapore, South Africa etc, and a likely hypothesis is that we are dealing with an aspect of language crossing (cf Rampton 1995) in an ethnically diverse urban London.
In my presentation, I intend to outline the various syntactic and pragmatic functions of the tags innit and is it, and correlate these linguistic findings with non-linguistic parameters such as socioeconomic class, age and location, thus determining whether sociological factors have a bearing on their distribution. Moreover, I will attempt to characterize the processes of reanalysis involved with
reference to the theoretical framework of grammaticalisation. Finally, I want to suggest certain other constructions which are possible candidates for a similar development.
My study draws on data from COLT.
This paper is concerned with the use of the word like as a pragmatic marker. It is an empirical study which draws primarily on data from The Bergen Corpus of London Teenage Language (COLT). The purpose is to present a pragmatic analysis of the pragmatic marker like within the framework of relevance theory, and in doing so, to show that relevance theory provides an adequate set of tools for the description of markers in terms of their pragmatic function.
What general description can relevance theory provide? The answer to this question requires an investigation of how the marker like has a bearing on the process of utterance interpretation, and more specifically how it is associated with the relevance-theoretic notions of contextual efforts and processing effort. It also requires an investigation of how the marker can be described in terms of three fundamental distinctions: the truth-conditional / non-truth-conditional distinction, the conceptual / procedural distinction and the explicit / implicit distinction. These distinctions, in conjunction with the crucial principle of relevance, constitute an adequate framework to account for the various uses. I will propose an analysis of like as a pragmatic marker of loose use of language, encoding a procedural constraint on the explicatures of utterances.
Most accounts of pragmatic markers are restricted to analytical descriptions of how the marker operates in actual usage. Assessing a marker in the light of a theory of communication based on cognitive principles allows us to proceed further in our account. My aim is to go beyond the merely descriptive analytical level by tentatively predicting certain restrictions on the application of like. An attempt at defining pragmatic rules that seem to constrain its usage is therefore an important by-product of my discussion.
In this paper I examine the use of certain highly frequent lexical items with mainly pragmatic functions, as they appear in the speech of London teenagers. Conversations from The Bergen Corpus of London Teenage Language (COLT) suggest that 'particles' such as like, cos, yeah,what and innit are developing new sentence-independent functions and becoming grammaticalised. For example, like has a wide range of uses, many of which are not covered by the labels which categorize this word in Standard English (eg verb, preposition, conjunction). Consider [1]:
[1]
![]()
![]()
<1>
but it wasn't like a long thing but like, I, the time that I spent with him was like quite a long time, like the evening, whatever, so he'd get, and like it just used to be constant pauses, it used to be terrible and so we used to get off with each other like you pause [for, for what]
<2>
[And you, did you like] did you were you attracted to him then?
<1>
Yeah I was really attracted to him but I just could not speak to him it was awful.
Interestingly, like has a Swedish (and Norwegian) counterpart, liksom (Kotsinas 1994:71), and wherever relevant, my discussion will include a comparison with the Scandinavian languages.
Consider also [2] and [3]:

Although the items to be discussed are used in different contexts in teenage speech, I argue that each of them is subject to a change in function, either from being syntactic elements to becoming pragmatic particles (like) or by developing new pragmatic functions (yeah, innit).
![]() COLT-based research
COLT-based research
In the Nordic countries, research into teenage language is carried out by
UNO (Språkkontakt och ungdomsspråk i
Norden), a project which aims at the investigation and comparison of spoken and informal
written language of Nordic teenagers.
Last revised 16th of June 1998 by Hanne Aas. and Lars T. Johannessen
The Bergen Corpus of London Teenage Language (COLT)
Department of English, University of Bergen, Sydnesplass 9, N-5007
Bergen, Norway.
Tel: +47 55 58 31 50 Fax: +47 55 58 94 55
![]()
![]()
![]()